Google API 사용없이 Youtube 영상을 mp3로 저장하기
목차
개요
Youtube 중 "김달림"님이라는 분이 계신다. 이 분의 커버 영상을 MP3로 변환하여 휴대폰에 저장하여 이동 중에 듣기도 하며 커버 영상을 틀어놓고 개발을 하거나 책을 읽기도 한다. 문제는 휴대폰에 저장하여 이동 중에 듣는다는 것인데 최신 커버 영상이 올라오면 따로 수작업을 통해 휴대폰으로 옮기는 과정이 매우 귀찮은 작업이라는 점이다.
그렇기에 커버 영상의 정보를 가져와 MP3 파일로 일괄 다운로드를 수행하는 스크립트를 만들어봤다. 적어놓고보니 목표로 하는 것은 간단해 보이지만 그 과정은 쉽지만은 않았는데 이 포스팅은 이 과정에 대한 기록을 해놓은 것이다.
1. Google API 없는 Youtube 정보 수집이 목표다.
개발에 있어 스스로 세워본 작은 목표는 Google에서 제공하는 Youtube API 없이 http 요청을 위한 requests와 html 파싱을 위한 BeautifulSoup만을 사용해보고자 했다. 사실 나 혼자 사용할 거라 YoutubeAPI를 사용하는 것이 편의성이 좋고 개발하기 속도도 좋은데 Yotube 같은 플랫폼에서는 어떤 방식을 통해 목표한 바를 달성할 수 있을지를 과정을 즐겨보고자 했다.
2. 데이터 수집 위치 결정과 2가지 이슈 살펴보기
온라인에서 제공되는 Youtube 영상 다운로드 기능들을 살펴보면 대부분 Watch URL을 입력받는다. 즉, Youtube 영상을 다운로드하기 위해서는 Watch URL이라는 것이 필요한 셈이다.
이번 구현에서는 하나의 영상만을 다운로드 하는 것이 아닌 지금까지 올린 모든 커버 영상이 대상이다. 그렇기에 모든 영상이 올라오는 페이지를 진입점(데이터 수집을 시작할 위치)으로 삼고 이 페이지를 기준으로 Watch URL을 수집할 수 있음을 예상했다.
모든 영상이 올라오는 페이지는 다음과 같다.
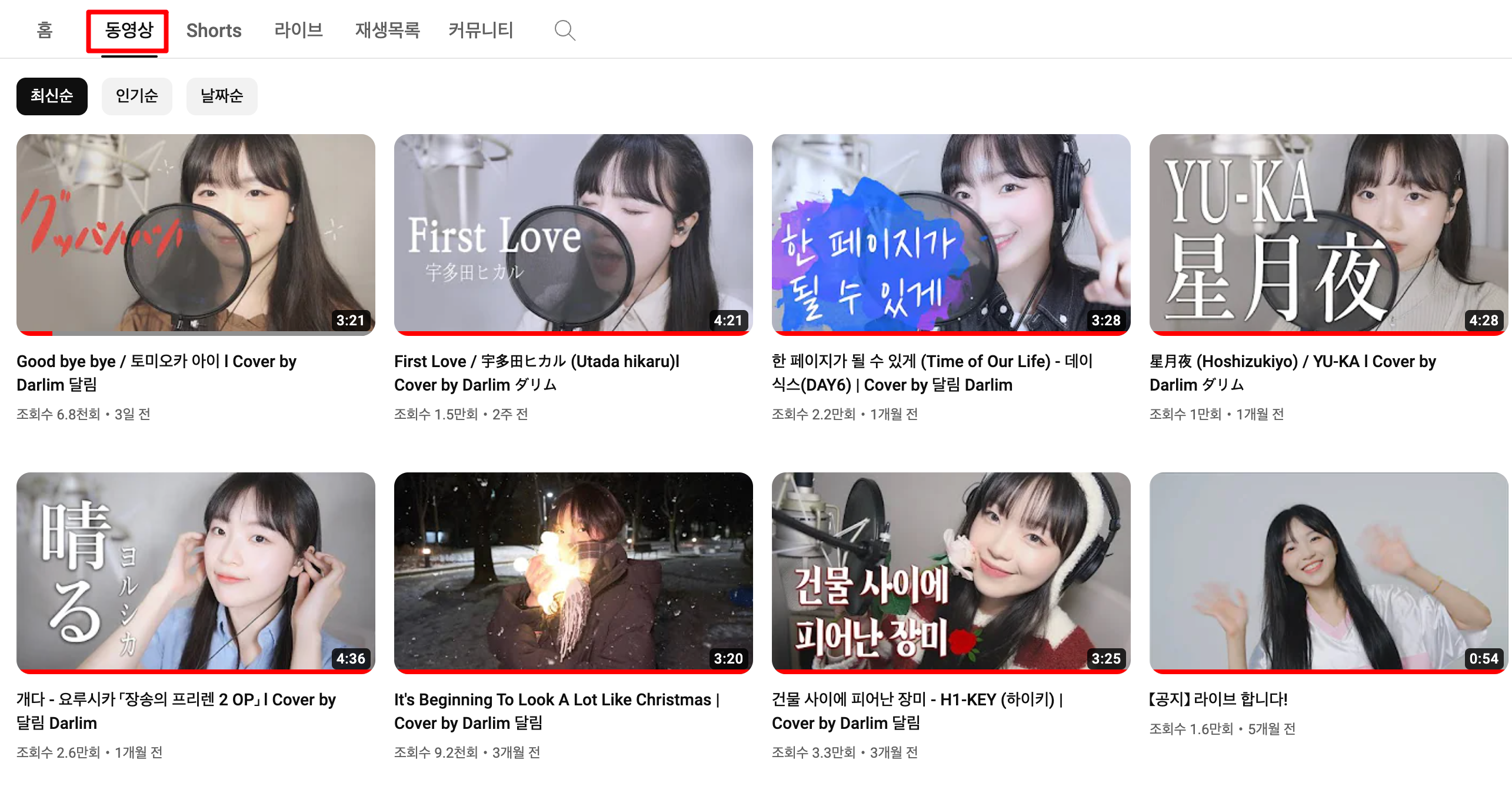
여기서부터 F12를 눌러 BeautifulSoup를 통해 HTML을 파싱 하거나 F12를 눌러 Network 트래픽을 디버깅하면 될 것 같지만 개발 중 다음과 같은 이슈가 있었다.
- 이 페이지를 기준으로 requests를 사용하여 BeautifulSoup로 HTML Parsing 시 Video에 대한 HTML 태그가 존재하지 않는다. 이는 동적 크롤링(Selenium)을 고려해야 하는 상황일 수 있다.
- F12를 눌러 Network 트래픽을 관찰하면 영상의 정보를 불러오는 EndPoint는 발견할 수 있지만 해당 EndPoint에서 요구하는 Paramter가 어디로부터 오는 정보인지 파악되지 않는다.
1번 이슈는 목표로 내세운 바에 부합되는 방법이 아니다. 시작부터 막히는 상황이다. 그러나 Yotube 페이지를 HTML 소스로 열어보면 영상관련 데이터가 <script> 태그에 들어있음을 알 수 있었다. 2번 이슈는 Network 트래픽에서 어떤 값을 보내는지 확인할 수 있으므로 앞서 확인한 <script> 태그에 들어있는 데이터로부터 몇 가지는 채워 넣을 수 있을 듯하다.
차근차근 해결하기 위해 1번 이슈부터 곰곰히 생각해 보자.
3. HTML 페이지 내에 존재하는 영상 관련 데이터
진입점으로 삼은 페이지에서 HTML 소스를 열어보면 다음과 같은 텍스트가 띈다.
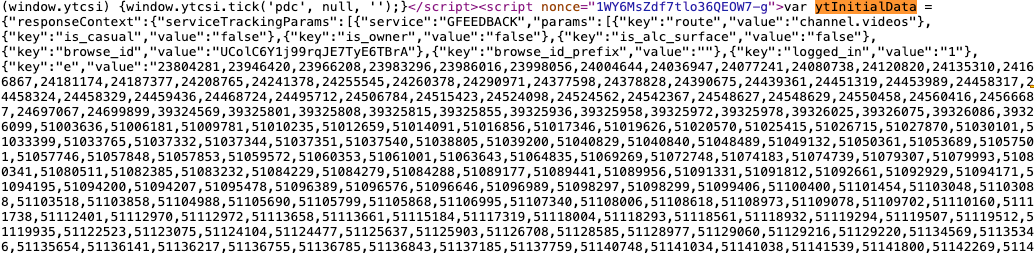
"ytInitialData"라는 JavaScript 변수이다. Youtube 개발자의 확답을 얻으면 좋겠지만 그러지 못하는 상황이니 변수명으로 추측해 보자면 진입점으로 삼은 페이지에 처음으로 로딩될 영상 관련 데이터 정보가 포함돼있지 않을까 싶다. 이를 Python에서 다루려면 BeautifulSoup로 script 태그를 뽑아서 text에 "ytInitialData"가 있는지를 체크해야 한다.
@cached_property
def get_ytb_initialdata(self):
""" JavaScript의 ytInitialData 얻기 """
_guess_exceed_number = 5000
for x in self.soup.findAll("script"):
if "ytInitialData" in x.text and len(x.text) > _guess_exceed_number:
return x.text
_guess_exceed_number라고 선언된 게 있는데 ytInitialData를 str로 다루다 보니 str의 길이를 통해 영상 데이터를 담고 있는 변수인지를 추측한 셈이다. 이 변수는 대량의 데이터를 포함하고 있는데 천천히 살펴보면 watch_url이 포함되어 있다.
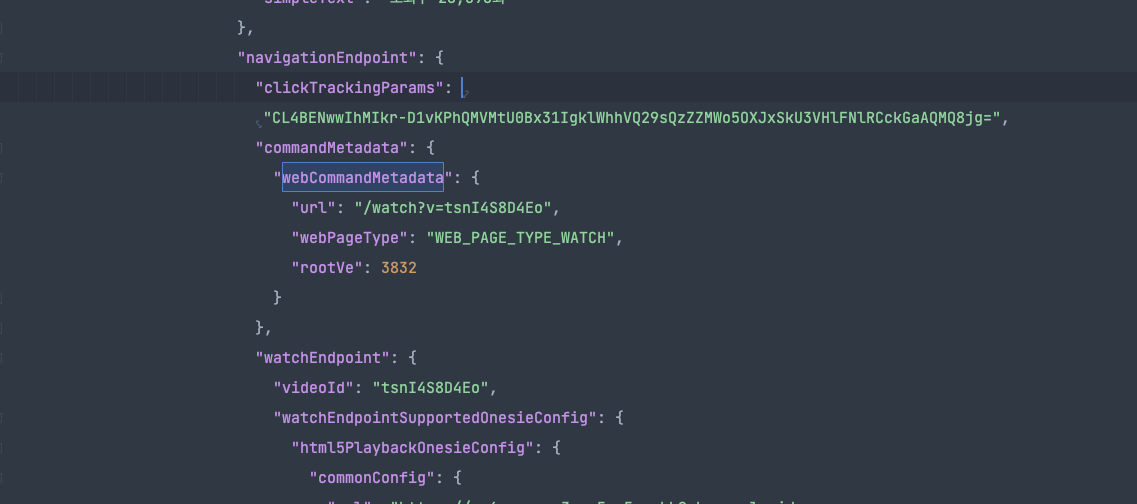
json으로 변환을 거치고 watch_url을 추적해도 되지만 정규표현식으로도 가능한지 시험해 봤다.
def get_urls_from_ytb_initialdata(self) -> List[str]:
pattern = r'"videoId":"([\w-]+)"'
urls = set()
for url in set(re.findall(pattern, self.scrapper.get_ytb_initialdata)):
urls.add(self.scrapper.convert_to_ytblink(url))
return list(urls)이렇게 얻어낸 watch_url의 수는 30개이다.
4. 인피니티 스크롤 방식의 데이터 로딩처리
앞선 과정에서는 유튜브 페이지에 로딩되는 초기 영상 데이터를 수집하는 방식이었다. 이후 로딩되는 데이터를 수집해야하는데 유투브 동영상 탭을 살펴보면 알 수 있듯 스크롤에 따라 데이터가 추가되는 인피니티 스크롤 방식이다. 유투부는 어떤 방식으로 데이터를 로딩하고 어떻게 수집할 수 있을까?
4.1 유투브 동영상 페이지의 추가 데이터 로딩
이쯤에서 유튜브 동영상 페이지를 열어놓고 추가 데이터가 로딩되는 상황에서 Network 트래픽을 살펴보면 다음과 같은 요청이 일어남을 알 수 있다.
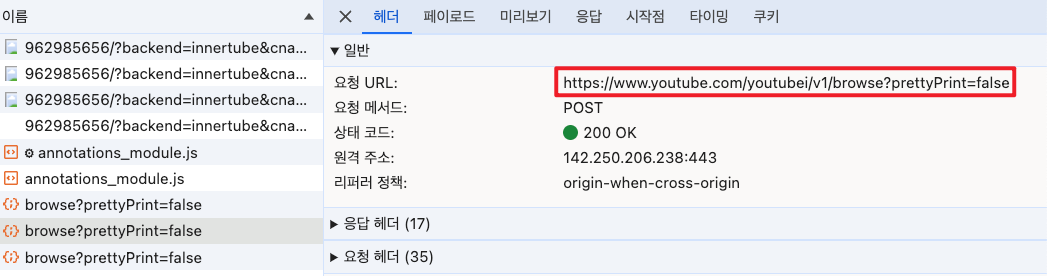
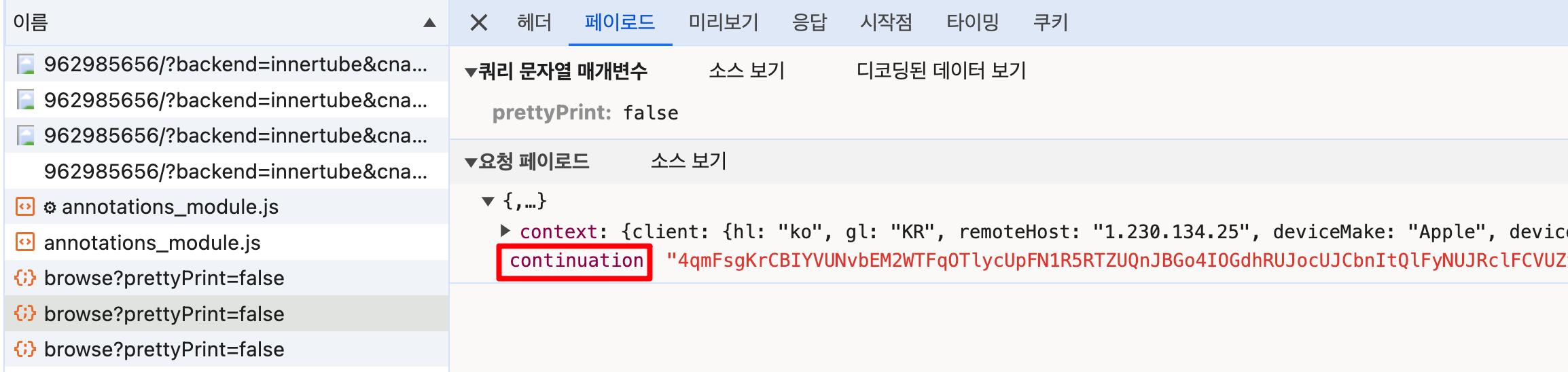
결과로부터 관찰되는 특징을 추측할 뿐이라 정확히 어떤 동작을 하는 것이라 단언할 수 없는 상황이다. 위와 같은 요청의 특징을 보니 추가 데이터를 로딩하려면 "continuation"이라는 요청 페이로드가 필요로 하는 것처럼 보인다. 그리고 추가로 context 정보가 필요한데 이는 대략 다음과 같이 생겼다.

꽤나 많은 데이터를 필요로 한다. 그러나 위에서 요구하는 데이터는 다 채울 순 없는 노릇이기 때문에 기존에 나와 같은 방식으로 진행한 Source가 있는지 github를 검색해 본 결과 다음과 같은 정보만 요청해도 무리 없는 걸 확인했다.
{
"context": {
"client": {
"clientName": "WEB",
"clientVersion": "2.20240322.01.00"
}
},
"browseId": "",
"continuation": ""
}
browseId는 Youtube Channel ID를 채우면 되지만 continuation은 정보는 어디서 가져오는 걸까?
4.2 추가 데이터 로딩에 필요한 continuation token
삽질을 통해 추가 데이터 로딩을 요청하기 위해 필요한 continuation token은 앞서 소개한 ytInitialData에 들어있음을 확인했다. 이 또한 정규표현식으로 찾을 수 있는데 문자열로 다루다 보니 대략 1000자 이상을 찾았다.
@cached_property
def get_continuation_token(self):
""" continuationCommand Token 얻기 """
pattern = r'"continuationCommand"\s*:\s*{"token"\s*:\s*"[^"]{1000,}"'
match = re.search(pattern, self.get_ytb_initialdata)
continuation_token = match.group(0).split(":")[-1]
return continuation_token.replace("\"", "")
continuationCommand를 찾는데 1000자 이상을 지정하는 데는 continuationCommand가 한 개 이상이기 때문이다.
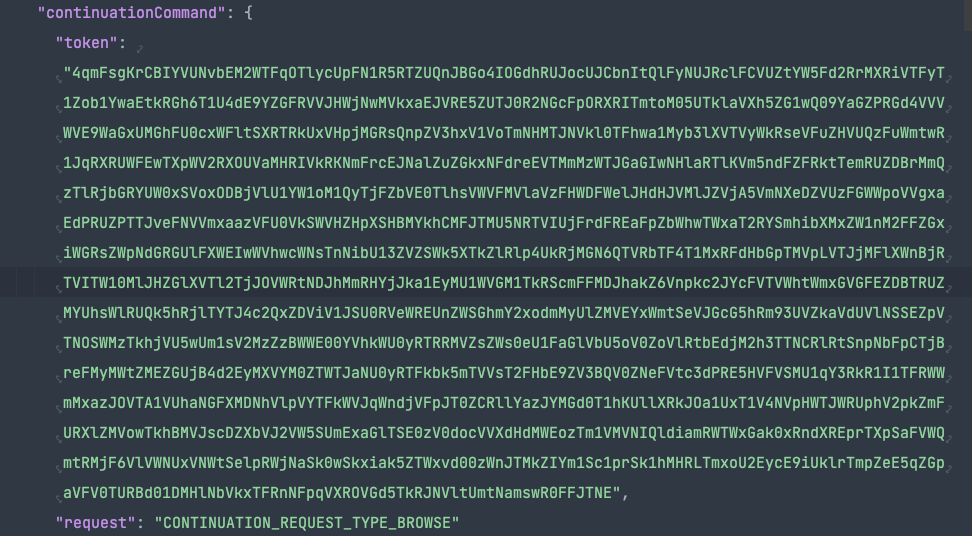

이 글을 작성하는 현시점에도 두 개의 token이 각각 어떤 용도인지 알지 못했다.
4.3 데이터 수집 3가지 포인트
앞서 얻은 continuation token을 통해 계속 같은 Enpoint에 요청을 날리면 추가 데이터가 로딩될 것 같지만 그렇지 않았다. 여러 삽질 끝에 다음과 같은 3가지 접근 포인트에서 데이터를 얻을 수 있었다.
- ytInitialData -> 30개
- continuation token을 포함한 요청 -> 30개
- continuation token을 포함하지 않은 요청 -> 24개
3번 방법은 삽질을 하다 우연찮게 알게 된 방법이다. continuation token을 포함하지 않고 channel_id만 요청 페이로드에 넣어도 watch_url을 얻을 수 있었다.
3가지 방법의 데이터 수량을 다 더하면 64개이다. 김달림 님 채널에 업로드된 영상은 24.03.26을 기준으로 63개이다. 그렇다 데이터 중복이 발생한다. 중복을 제거하고 보니 총 62개의 watch_url을 수집했는데 이는 총 63개에서 1개가 빠지기 때문에 데이터 누락이 발생됨을 뜻했다.
그러나 아쉽게도 누락된 데이터를 찾아 얻어내는 방법을 알아내진 못했다.
5. Python으로 Youtube Video Download
이제 watch_url 수집을 대략 마쳤으니 수집한 URL을 통해 영상을 파일로 다운로드할 차례다. Python에서는 Youtube 영상을 다운로드하기 위해 조사한 라이브러리에는 pytube가 있었다. 해당 라이브러리를 쓰던 중에 연령 제한이 걸리는 이슈가 존재했다.
[BUG] AgeRestrictedError: ZfpgKWTQqXw is age restricted, and can't be accessed without logging in. · Issue #1712 · pytube/pytu
I applied use_oauth and allow_oauth_cache, but the error is still poping up. yt = YouTube(url,use_oauth = True, allow_oauth_cache=True) yt.streams.get_highest_resolution().download(output_path=save...
github.com
Open 중인 Issue이며 이를 해결하기 위해서 다운로드한 pytube 소스를 수정하는 방법들이 있음을 알게 됐는데 이러면 "라이브러리"를 받아서 사용하는 의미가 없었다. 또한 소스를 수정하여 해결하여도 HTTP 403, 410, 413 이슈들이 터져 pytube를 사용하지 않는 방법을 강구했다.
다행히도 pytube를 대신할 라이브러리를 찾았는데 "yt-dlp"라는 라이브러리였다.
yt-dlp
A youtube-dl fork with additional features and patches
pypi.org
해당 라이브러리를 사용하여 영상을 다운로드하다가 알게 된 사실인데 mp4와 같은 영상 데이터를 mp3로 변환하려면 "yt-dlp"에서는 ffmpeg 바이너리를 필요로 했다. 그러나 이는 꼼수로 파일의 확장자를 "mp3"를 대체시켜 버리는 방식으로 해결해 버렸다.
6. Conclusion
이런 과정을 거쳐 나온 유튜브 영상 다운로드는 다음과 같이 동작한다.
이 글을 읽고 같은 주제에 흥미를 가지시거나 도전해보실 분들을 위해 이 프로젝트에 대한 링크를 남기도록 하겠다.
GitHub - jak010/darlownload: 달운로드
달운로드. Contribute to jak010/darlownload development by creating an account on GitHub.
github.com
마치며
스스로가 필요하기 때문에 코드를 작성해 스크립트를 만든 건 오랜 간만의 경험이다. requests와 BeautifulSoup를 사용하지 않은 채 데이터를 로딩 방식을 분석하고 재연시키는 과정을 추적하는 게 어려웠고 그 결과로 데이터 누락도 발생했다. 그리고 아직 이렇게 다운로드한 로컬에 존재하는 파일을 휴대폰을 이동시키는 과정도 수동적으로 옮겨야 한다.
이 작업을 시작하기 전에 상상했던 목표 중 하나는 Python Kivy를 활용해 개인 휴대폰에 설치하고 주기적으로 체크하여 업데이트하는 방식이었다. 이렇게 하면 "자동화"를 달성하는 셈이기도 하니 다뤄보면 좋겠지만 Google API 없이 Youtube 데이터를 수집하고 추가 데이터 로딩 방식을 파악하고 적용해 놨다는 것에 만족해보려 한다.